
Chinchilla scaling laws?
- Current LLMs are significantly undertrained.
- Given a fixed FLOPs budget,1 how should one trade-off model size and the number of training tokens?

- For compute-optimal training, the model size and the number of training tokens should be scaled equally.
- Chinchilla (70B, 4x data) > Gopher (280B)
Llama
- The focus of this work is to train a series of language models that achieve the best possible performance at various inference budgets, by training on more tokens than what is typically used. → 기존 chinchilla 연구는 이를 간과하고 있음
- ranges from 7B to 65B parameters
- LLaMA-13B (10x smaller) > GPT-3 → “democratize the access and study of LLMs”
- LLaMA-65B > Chinchilla, PaLM-540B
- only use publicly available data
Alpaca
- Fine-tuned Llama 7B model
- 52K instruction을 따르도록 훈련
- Self-instruct 파이프라인 사용
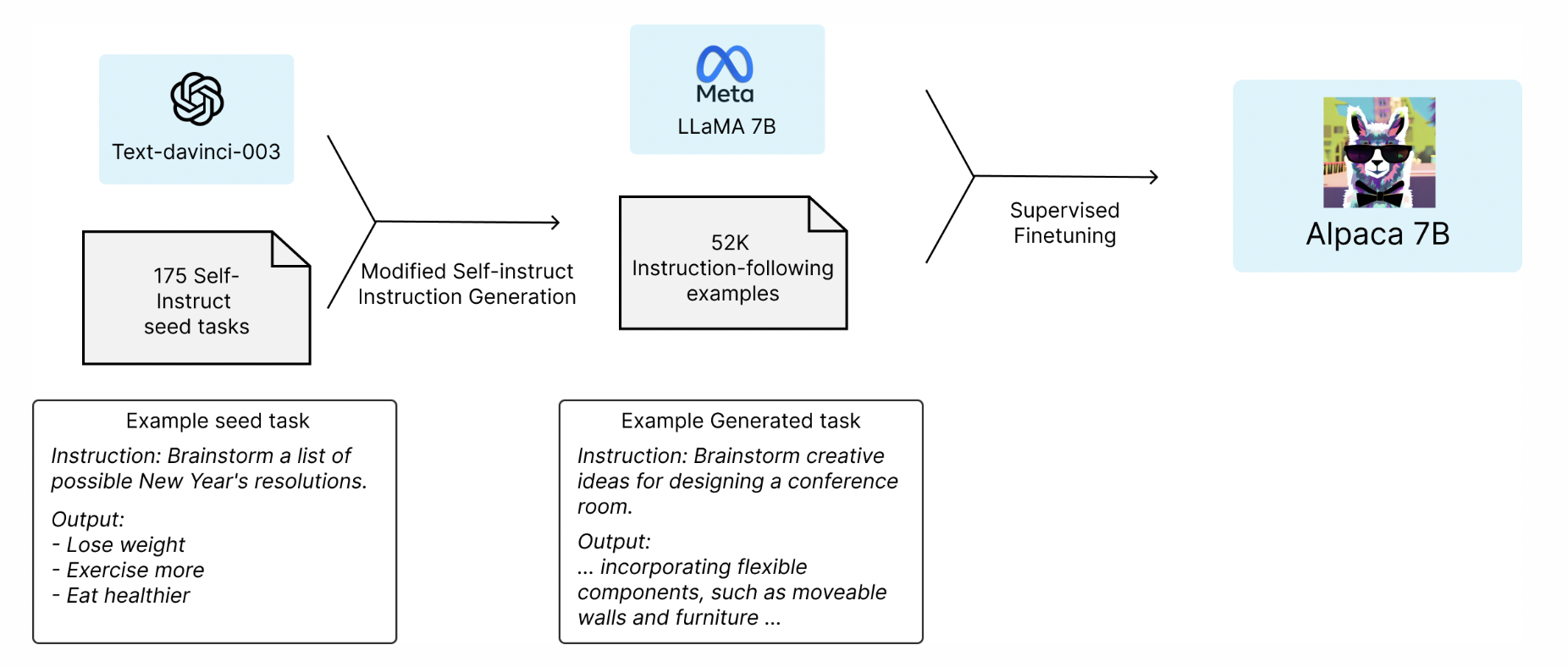
Sources to help infer/fine-tune Alpaca
Stanford Alpaca Repo
https://github.com/tatsu-lab/stanford_alpaca#recovering-alpaca-weights
Alpaca-lora Repo
https://github.com/tloen/alpaca-lora
https://colab.research.google.com/drive/1eWAmesrW99p7e1nah5bipn0zikMb8XYC#scrollTo=w3_lzwcqermJ (demo)
A brief history of LLaMA models
'Research > NLP' 카테고리의 다른 글
| Generation Configuration - 생성 인퍼런스에 사용되는 config 이해하기 (0) | 2023.07.16 |
|---|---|
| Pre-training LLM 분류하기 (Encoder, Decoder, Encoder-Decoder) (0) | 2023.07.16 |
| [LLM 모음] InstructGPT의 훈련 과정 알아보기 (feat. RLHF) (1) | 2023.06.04 |
| 강화학습과 InstructGPT - part 1 (0) | 2023.05.28 |
| [Paper review] Larger language models do in-context learning differently (번역정리) (0) | 2023.05.21 |



