이전 포스트에서 LLM을 효율적으로 훈련하는 방법 중 하나로 '양자화'를 소개하였습니다.
https://yooonlp.tistory.com/21
LLM 효율적으로 훈련하기 - 양자화(Quantization)와 분산 훈련(Distributed Training)
※ 본 포스트는 Coursera 강의인 "Generative AI with Large Language Models"의 Week 1의 내용의 일부를 정리하고 필요한 내용을 추가하여 작성한 글입니다. GPU를 사용하여 모델 훈련을 진행하다 보면 “CUDA out o
yooonlp.tistory.com
4byte를 차지하는 FP32 데이터 타입에서 2byte를 차지하는 BF16/FP16 데이터 타입을 사용한다면 모델 사이즈를 절반으로 줄일 수 있고, inference 성능에서 큰 차이가 나지 않는다고 합니다. 여기에서 모델 사이즈를 더 줄일 수 있다면 좋겠지만, inference 성능 또한 대폭으로 감소한다고 합니다. 성능 감소를 해결하면서도 사이즈를 줄이기 위해 8-bit 양자화 방법이 LLM.int8() 논문에서 소개됩니다. 본 포스트에서는 bitsandbytes의 골자가 되는 LLM.int8()의 개념을 간단하게만 소개하고, 이 라이브러리를 사용하는 방법에 대해 알아보고자 합니다.
8-bit Quantization
기존의 8bit 양자화에는 Zeropoint quantization과 Absmax(absolute maximum) quantization 두 가지 방법이 있습니다. Zeropoint 양자화는 사용 가능한 데이터 타입의 전체 비트 범위를 사용하여 원래의 데이터를 표현하는 데에 더 정확할 수 있지만, 구현상의 복잡도로 인해 absmax 양자화 방식이 더 선호된다고 합니다. Absmax 양자화는 주어지는 데이터 내의 절대 최댓값을 기반으로 양자화하며, 대칭적이기 때문에 구현이 더 쉽습니다. 이 두 가지 양자화 방식 모두 텐서 당 한 개의 scaling constant를 사용하는 데, 이 방식의 치명적인 단점은 한 개의 outlier가 다른 값의 양자화 정밀도를 감소시킨다는 것입니다. 이를 해소하기 위해 텐서 당 여러개의 constant를 가지게 하여, block-wise constants로 outlier의 영향력을 block 안에서만 유효하도록하거나 더 나아가 row-wise quantization을 하는 연구들이 등장하였습니다.
LLM.int8()
LLM.int8() 의 핵심 요소는 vector-wise quantization과 mixed-precision decomposition입니다. 기존의 scaling constant 문제를 해결하기 위해 더 개선된 방식인 vector-wise quantization을 제안하였고, 6.7 Billion이 넘는 모델들에는 이 방법론으로는 부족하여 mixed-precision decomposition을 제안하였고 논문에서는 이것이 LLM.int8()의 코어라고 이야기합니다. Mixed-precision decomposition 방법론에서는 0.1%의 outlier만 16-bit로 나타내어지고, 99.9%의 값들은 8-bit로 matmul 계산이 됩니다.
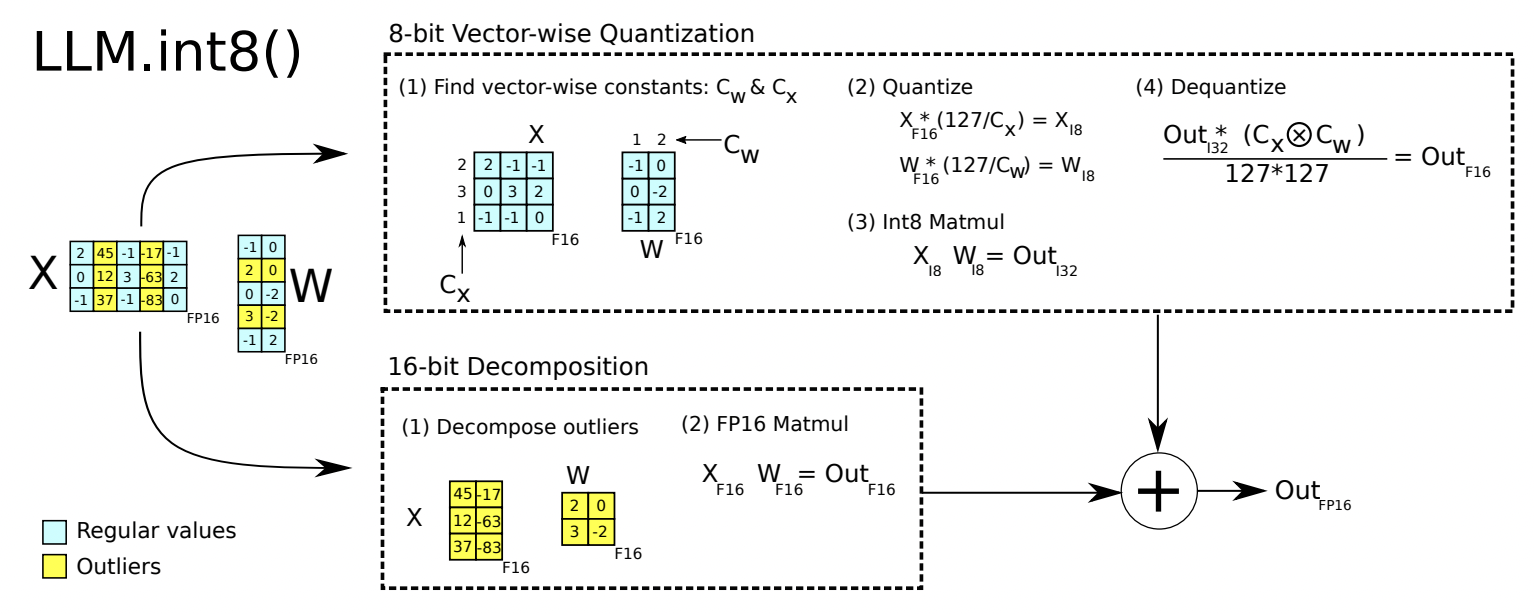
이 포스트를 작성하면서 헷갈렸던 지점은 LLM.int8()은 계산 과정에서의 양자화에 대하여 이야기하는 것이지, 기존에 inference를 위한 양자화라고 알고 있던 모델 사이즈를 줄이는 것과는 다른 것 같다는 점이었습니다. 위의 그림을 보아도 output은 fp16이지 int8이 아닌 것을 볼 수 있습니다.
제가 이해한 바로는 본 논문에서는 FP16 모델을 받아, 8-bit로 계산한 후 다시 FP16으로 dequantize를 하며, 이때 dequantize된 값은 정밀도가 거의 손실되지 않는다는 것을 보여줍니다. 즉 계산 과정에서의 양자화를 하여 리소스를 줄이는 것에 대해 이야기하고 있으며, output은 FP16이고 최종 모델 사이즈를 줄이는 것은 언급되지 않습니다.
LLM.int8()이 기반이 되는 bitsandbytes 라이브러리를 통해 int8 모델로 저장하기 위해서는, 위 그림의 8-bit Vector-wise quantization에서 dequantize를 하지않고, mixed-precision decomposition에서 16bit를 사용하지 않으면 8bit 모델로 저장할 수 있을 것입니다. 다음 튜토리얼을 통해서 간단한 fp16 모델을 int8 모델로 변환해봅시다.
간단한 모델을 int8로 변환해보기
이와 같은 알고리즘은 bitsandbytes를 사용하여 손쉽게 사용할 수 있습니다. 간단한 torch 모듈을 이 라이브러리를 사용하여 int8로 변환하는 방법에 대해 알아보도록 하겠습니다. Huggingface blog의 튜토리얼을 참고하였습니다.
1. 먼저 다음 라이브러리들을 import합니다.
import torch
import torch.nn as nn
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt
2. 간단한 linear 모델을 정의합니다. 이론적으로는 FP32, BF16, FP16 모두 8-bit로 변환 가능하지만, 현재는 FP16 모델만 가능하다고 합니다. 정의된 모델을 훈련하고, 가중치를 저장합니다.
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)
#### 훈련 코드 생략 ####
torch.save(fp16_model.state_dict(), "model.pt")
3. 정의했던 FP16 모델을 기반으로, Linear8bitLt을 활용하여 int8 모델을 재정의합니다. Linear8bitLt는 nn.Linear를 상속받는 클래스로 내부에서 가중치를 int8로 변환하도록 합니다. 효율적인 inference를 위해서 has_fp16_weights=False로 설정해주어 가중치를 int8로만 설정합니다. 디폴트값은 int8/fp16 mixed precision으로 설정됩니다.
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)
4. 저장해둔 가중치를 int8 모델에 로드합니다.
int8_model.load_state_dict(torch.load("model.pt"))
int8_model = int8_model.to(0) # 여기에서 양자화가 진행됩니다
int8_model.to(0)를 실행하기 전/후를 비교해보면, 가중치가 [-127, 127] 사이에 분포해있으며, 값이 일정 부분 잘려나간 것을 보실 수 있습니다.
실행전:
tensor([[ 0.0031, -0.0438, 0.0494, ..., -0.0046, -0.0410, 0.0436],
[-0.1013, 0.0394, 0.0787, ..., 0.0986, 0.0595, 0.0162],
[-0.0859, -0.1227, -0.1209, ..., 0.1158, 0.0186, -0.0530],
...,
[ 0.0804, 0.0725, 0.0638, ..., -0.0487, -0.0524, -0.1076],
[-0.0200, -0.0406, 0.0663, ..., 0.0123, 0.0551, -0.0121],
[-0.0041, 0.0865, -0.0013, ..., -0.0427, -0.0764, 0.1189]],
dtype=torch.float16)실행후:
tensor([[ 3, -47, 54, ..., -5, -44, 47],
[-104, 40, 81, ..., 101, 61, 17],
[ -89, -127, -125, ..., 120, 19, -55],
...,
[ 82, 74, 65, ..., -49, -53, -109],
[ -21, -42, 68, ..., 13, 57, -12],
[ -4, 88, -1, ..., -43, -78, 121]],
device='cuda:0', dtype=torch.int8, requires_grad=True)
다음 코드를 실행하여 int8 값에서 fp16을 다시 불러와 볼 수 있습니다(dequantize). 조금의 차이는 있지만, 기존의 fp16 값에 가깝습니다.
(int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127
5. int8로 양자화된 모델에 input을 넣어 inference를 진행할 수 있습니다.
input_ = torch.randn((1, 64), dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))
이번 포스트에서는 int8 양자화와 LLM.int8() 알고리즘을 소개하고, 이 방법을 활용하여 아주 간단한 linear 모듈을 int8로 변환하는 기본적인 방법을 알아보았습니다. bitsandbytes는 transformers, accelerate 등 여러 다른 라이브러리를 통해서 쓸 수 있도록 되어있는데, 다음 포스트에서는 transformers 모델을 양자화하는 방법과 이를 사용하는 조건들에 대해서 알아보겠습니다.
Reference
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (LLM.int8() paper)
- bitsandbytes github (TimDettmers/bitsandbytes)
- A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes (Blog post from Huggingface)
- LLM.int8() and Emergent Features (Blog post from Tim Dettmers)
'Research > NLP' 카테고리의 다른 글
| [논문리뷰] Searching for Best Practices in Retrieval-Augmented Generation (0) | 2025.02.01 |
|---|---|
| [논문리뷰] Reliable, Adaptable, and Attributable Language Models with Retrieval (0) | 2024.08.10 |
| LLM 효율적으로 훈련하기 - 양자화(Quantization)와 분산 훈련(Distributed Training) (0) | 2023.08.01 |
| LoRA 이해하기(Low-Rank Adaptation of Large Language Models) (0) | 2023.07.16 |
| Generation Configuration - 생성 인퍼런스에 사용되는 config 이해하기 (0) | 2023.07.16 |



