본 포스트는 2021년 Microsoft에서 발표한 "LoRA: Low-Rank Adaptation of Large Language Models" 논문을 이해하기 위해 작성하였습니다.
2021년에 발표한 시점에서 자연어처리 응용분야의 큰 패러다임은 Bert, Roberta와 같은 사전 훈련된 언어 모델을 Fine-tuning하는 것이었습니다. 파인튜닝은 사전 훈련 모델의 모든 weight을 업데이트하는 방법론입니다. 하지만 사전 훈련 모델, LLM의 크기가 점점 커지면서, 이 거대한 모델 전체를 매번 파인튜닝하고 배포해야하는 문제에 봉착하게 됩니다. 일부 weight만을 업데이트한다면 사전 훈련 모델 외에 특정 weight만 저장하고 불러오면 되기 때문에 배포 시 운영 효율성이 향상되지만, 이러한 시도를 한 기존 연구들에서는 inference latency가 발생하거나, baseline 성능에 도달하지 못하는 한계점들이 있었습니다. 이번 포스트에서는 기존의 문제점을 해결하기 위해 소개된 LoRA에 대해서 이해해보고자 합니다.
Key Concepts
논문의 도입부에서는 LoRA에 사용된 주요 개념을 다음과 같이 소개하고 있습니다.
When adapting to a specific task, Aghajanyan et al. (2020) shows that the pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace. Inspired by this, we hypothesize the updates to the weights also have a low “intrinsic rank” during adaptation.
Pre-trained language model이 "low intrinsic dimension"를 가진다는 말은, 사전 훈련 모델의 가중치가 현재 가진 차원 수보다 훨씬 더 적은 차원 수로 표현될 수 있다는 것을 의미합니다. 모델이 거대한 가중치 행렬을 가지고 있지만, 사실상 그 안의 실질적인 의미는 더 적은 차원으로도 표현될 수 있다는 의미입니다. 이 아이디어를 adaptation 과정에 적용하여, LoRA에서는 모델 가중치 업데이트(ΔW)를 저랭크(Low-Rank) 행렬로 표현하게 됩니다. 여기서 '저랭크'라는 개념은 어떤 행렬이 그 행렬의 차원에 비해 상대적으로 적은 독립적인 정보를 가지고 있는 것을 의미합니다.
일반적인 fine-tuning 과정에서는 전체 가중치 행렬(W)에 대해 업데이트(ΔW)를 직접 수행합니다. 이는 모든 가중치를 계속 업데이트하고, 이를 원래의 가중치에 더하는 것을 의미합니다. 그러나 이 방법은 많은 계산량을 요구하고 거대한 가중치를 저장해놓아야하기 때문에 비효율적이라는 단점이 있습니다.
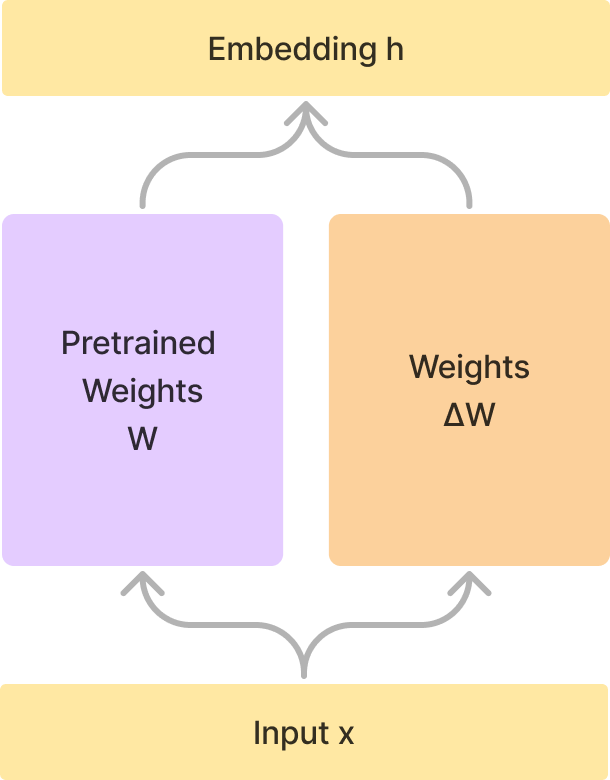
하지만, LoRA 페이퍼에서는 가중치 업데이트에 대해서 다르게 접근합니다. 가중치 행렬의 업데이트(ΔW)를 두 개의 저랭크 행렬 A와 B의 외적으로 표현하는 것입니다.
W0 + ∆W = W0 + BA
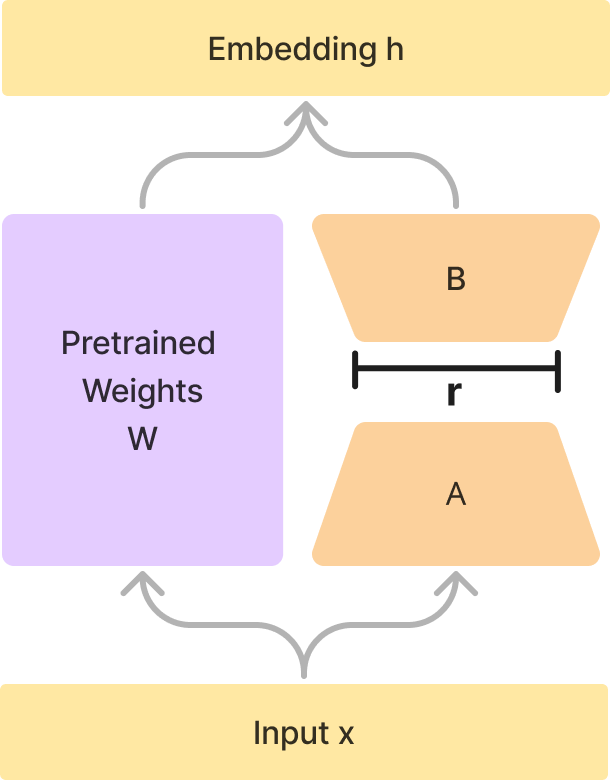
사전 훈련된 가중치 W0와 가중치 업데이트 ∆W에서 업데이트를 저랭크 행렬 분해(low-rank decomposition)를 통해 BA로 표현합니다. W0는 frozen weight이며, A와 B 각각 훈련 가능한 파라미터를 포함하고 있습니다. B는 d×r 크기의 행렬이고, A는 r×k 크기의 행렬입니다. 이 때, r은 행렬 B와 A의 공통된 차원으로, 행렬 분해의 랭크를 결정합니다. 이 랭크 값은 d와 k 중에서 작은 값 이하로 설정됩니다. 이 두 행렬은 각각 크기가 작기 때문에, 모델의 복잡성을 크게 줄일 수 있습니다. 이러한 방식을 사용하면 가중치 행렬의 크기가 크더라도, 실제로 업데이트되는 부분은 저랭크 행렬인 A와 B만큼이므로 계산량을 크게 줄일 수 있습니다. 또한, 가중치 행렬을 직접 변경하지 않고 A와 B를 별도로 유지하므로, 원래 가중치 행렬의 정보도 보존할 수 있습니다. 이렇게 업데이트된 가중치는 훈련 단계에서만 사용되고, 실제 inference 단계에서는 원래의 가중치 행렬을 그대로 사용하므로 추가적인 연산이 필요 없습니다.
Inference Latency?
훈련 과정에서 입력 데이터를 모델에 통과시킨 후 가중치의 업데이트를 적용하는 과정(W0 + ∆W)이 필요합니다. 그리고 이 업데이트는 원래의 가중치와 결합되어 새로운 가중치를 만듭니다. 하지만 이 과정은 연산량이 많아 추론 시점에서는 비효율적일 수 있습니다.
본 페이퍼에서는 다르게 접근을 하는데, 훈련 과정에서는 A와 B 두 행렬을 계속 업데이트하면서 진행하지만, 추론 시점에서는 훈련 과정에서 계산한 사전 훈련된 가중치와 업데이트된 저랭크 행렬들을 미리 결합하여 새로운 가중치를 만들어 놓습니다. 이는 실제 추론 과정에서 추가적인 연산을 필요로 하지 않으므로, inference latency가 없다고 볼 수 있습니다. 그렇기 때문에 LoRA는 추론 과정에서 높은 효율성을 보장합니다.
또한, 이 A와 B 행렬은 원래의 ΔW와 동일한 정보를 표현하지만, 이를 분해된 행렬 형태로 표현하므로 적은 연산량과 저장 공간으로도 충분히 모델을 업데이트하고 사용할 수 있다는 장점이 있습니다. LoRA는 큰 모델을 빠르고 효율적으로 추론할 수 있는 방법을 제공하기 때문에 LLM을 다루는 데에 있어서 매우 가치있는 방법론이라고 평가를 받습니다.
LoRA를 Transformer에 적용하기
Transformer 구조에는 self-attention에서 (W_q, W_k, W_v, W_o)의 네 개의 가중치 행렬과 MLP에서 두 개의 행렬이 존재합니다. 하지만 본 연구에서는 LoRA를 attention 가중치에만 적용하고 나머지 가중치는 그대로 둡니다.
왜 LoRA를 적용하는 것이 좋을까요? 작은 크기의 행렬을 사용하면 전체 모델의 가중치는 생각하지 않아도 된다는 장점이 있습니다. 그렇기 때문에 논문에서는 GPT-3를 훈련할 때, VRAM 사용량을 1.2TB에서 350GB로 줄이고, 랭크 4로 하여 W_q, W_v만을 변형한 훈련에서는 체크포인트의 크기가 350GB에서 35MB로 약 만배 정도 줄었다고 합니다.
다음은 GPT-3 175B 모델에 다양한 adaptation 방법론을 적용한 결과입니다. LoRA를 적용한 모델이 세 개의 데이터셋에 대하여 파인튜닝 베이스라인과 동일하거나 이를 넘는 성능을 보여주며, 다른 adaptation과 비교했을 때, 파라미터를 크게 줄이면서도 높은 성능을 보여주고 있습니다.

또한 가장 적합한 랭크를 찾기 위해 실험한 결과, 아주 적은 랭크로도 좋은 결과를 낼 수 있다는 것을 발견합니다. 가중치 업데이트 ∆W가 매우 작은 "intrinsic rank"를 가진다고 할 수 있으며, 랭크를 높인다고 해서 성능이 크게 향상되지는 않습니다.

정리하자면, LoRA를 사용하면 원래의 모델에 대한 행렬 분해를 사용하여 가중치 업데이트를 효율적으로 수행할 수 있습니다. 가중치의 변화를 작은 행렬로 표현할 수 있으며, 메모리를 크게 절약하고 훈련 속도를 향상시킬 수 있습니다. 또한 LoRA를 사용한 다양한 downstream task의 훈련 결과는 작은 행렬로 표현되므로, 추론 시점에서도 이를 쉽게 변경하거나 교체할 수 있습니다. 따라서 하나의 기본 모델을 사용하여 다양한 작업을 수행하고, 빠르게 작업을 전환할 수 있습니다.
References
- LoRA paper: https://arxiv.org/abs/2106.09685
- LoRA를 잘 설명한 영상: https://www.youtube.com/watch?v=dA-NhCtrrVE
'Research > NLP' 카테고리의 다른 글
| LLM.int8()과 bitsandbytes를 활용하여 int8로 모델을 양자화하는 방법 (0) | 2023.08.13 |
|---|---|
| LLM 효율적으로 훈련하기 - 양자화(Quantization)와 분산 훈련(Distributed Training) (0) | 2023.08.01 |
| Generation Configuration - 생성 인퍼런스에 사용되는 config 이해하기 (0) | 2023.07.16 |
| Pre-training LLM 분류하기 (Encoder, Decoder, Encoder-Decoder) (0) | 2023.07.16 |
| [LLM 모음] Llama와 Alpaca (0) | 2023.06.11 |



