과거에 논문 스터디를 진행하면서 작성해놓았던 논문 리뷰를 포스트로 공유합니다. Continual Pretraining 하위 개념인 DACP, TACP에 대한 실험을 참고하실 수 있습니다.
ArxivID: https://arxiv.org/pdf/2311.08545
Last edited time: September 10, 2024 7:11 PM
Topic: Continual Pretraining
정독 필요: No
잘 설명된 한국어 블로그: https://introduce-ai.tistory.com/entry/논문-리뷰-Efficient-Continual-Pre-training-for-Building-DomainSpecific-Large-Language-Models
연구 질문
Domain-adaptive continual pretraining (DACP) 이
domain-specific LLM을 만드는데 유용한가?
→ Pretrained 모델 훈련 데이터의 8% 크기의 도메인 데이터로 금융 벤치 성능 향상
효과적인 훈련을 위해 data selection strategies를 사용할 수 있는가?
→ 도메인 데이터의 10% 또는 사전학습 데이터 0.8% 만으로도 도메인 성능 향상
이 훈련이 open domain 능력을 떨어뜨리는가?
→ open domain 데이터셋으로 평가했을 때 여전히 범용 성능을 유지한다
연구 Contribution
- financial corpus curation
- Domain data를 scratch로 pretraining하는 것보다 저비용으로 대안 삼을 수 있다.
- Vanilla 방법보다 더 효율적인 Data selection 전략들을 소개한다.
연구 방법
Domain-adaptive Continual Pre-training
- Domain Adaptive Pretraining
- 정답이 없는 큰 도메인 코퍼스에 대해 사전 훈련을 이어나감
- 엄청난 양의 데이터를 훈련시키기 때문에 비용이 많이 듦
- (선행 연구) PRETRAINED LANGUAGE MODEL IN CONTINUAL LEARNING: A COMPARATIVE STUDY
- Continual learning 이란, 새로운 데이터에 대한 지식을 축적할 수 있는 방법
- 관건은 이전에 사전 학습에 사용했던 지식을 잊지 않고 새로운 지식을 집어넣을 수 있는가?
Task-adaptive Continual Pre-training
- Task Adaptive Pretraining
- 주어진 태스크를 위한 성능 향상을 위해 (태스크 레이블 있든 없든) 훈련 데이터에 대해 pretraining을 하는 방식
- task-specific LLM을 만듦
- 훨씬 더 작은 데이터셋을 사용함 → 애초에 데이터가 많이 없음.
- 주료 소형 모델에 대한 연구가 많이 이루어짐.
- (선행연구) Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
- task dataset으로 pretraining하는 것은 task 성능 향상에 기여함
- DAPT, TAPT에 대해 언급하는 논문
- DAPT and TAPT complement each other
DACP 비용이 많이 듦, TACP 데이터가 너무 없음
논문에서 제안하는 방식 → DACP + TACP를 합치자!
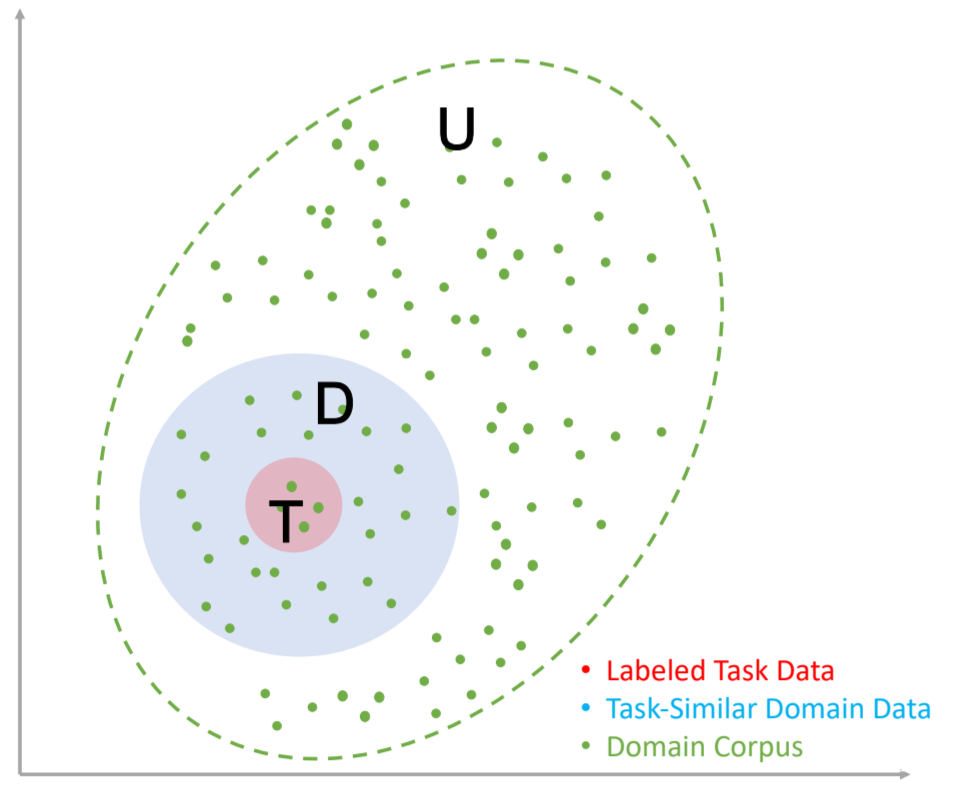
Raw Domain Corpus (U)가 있고,
ex. 의료 말뭉치
도메인 내의 라벨링된 Task Data (T) 가 있다고 가정 (단일, 다중 태스크 모두 가능)
ex. 의료 텍스트 요약 task: (in) 의료 보고서 → (out) 주요 진단 내용 요약
Data Selection의 목표: LLM 사전학습에 유용한 D를 선택하는 것.
(이렇게 하면 pretrain동안에 domain 적응이 되고, task에도 align이 될 것이다)
두 가지 data selection strategies
- task-similar (ETS) - task data가 있는 경우
- task-agnostic (ETA) - task data가 없는 경우
Data Selection: Formulation for ET{A,S}-DACP
- 데이터 선택 문제
- Pre-training Objective
- Generalization bound
결론
우선 본 연구에서 pythia 가지고 continual pretraining 한 결과
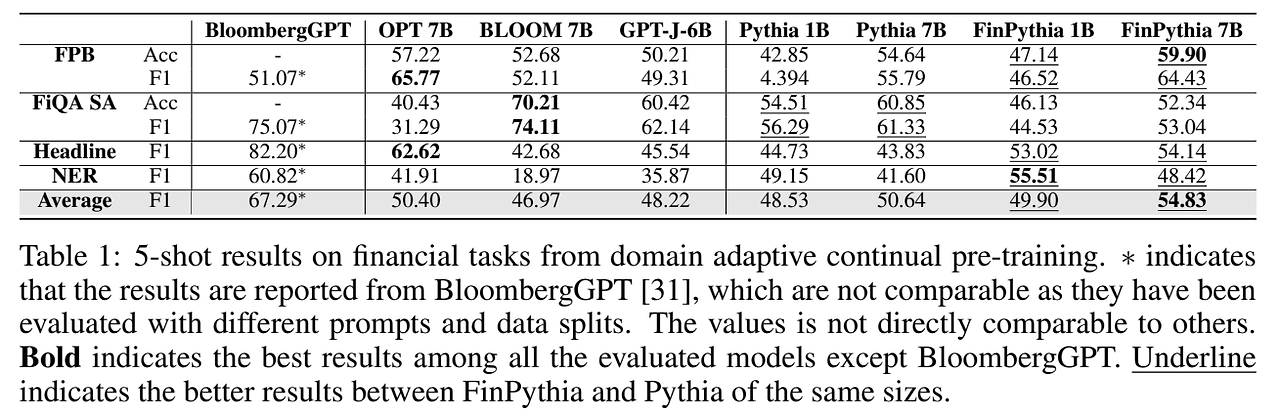
- 오픈 소스 백본 모델들에 대한 금융 데이터 테스트
- FinPythia 7B는 18일 소요, 1B는 3일 소요 → 24B 토큰
- 정성 평가

연구에서 제안한 ETS, ETA 비교
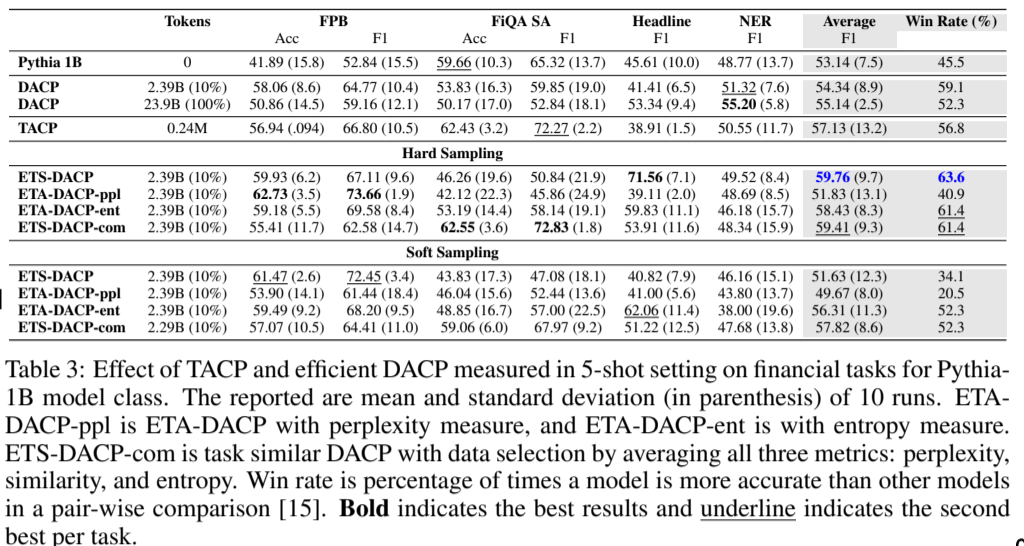
- 이 결과는 라벨이 없는 Task 데이터를 가지고 LLM에 task-adaptive 및 domain continual pre-training을 수행하는 것이 효과적임을 뒷받침하며, 이는 다른 모델 유형에서 관찰된 결과와 일치한다
- 또한, 도메인 데이터의 10%(2.39B)는 Pythia가 원래 학습한 3,000억 개의 토큰 중 1% 미만에 해당한다.
- 적은 학습량을 통한 도메인 성능 향상은 continual pre-training 과정에서 데이터를 선택적으로 선별하는 것이 적은 비용으로 도메인 성능에 큰 영향을 미칠 수 있음을 보여준다.



